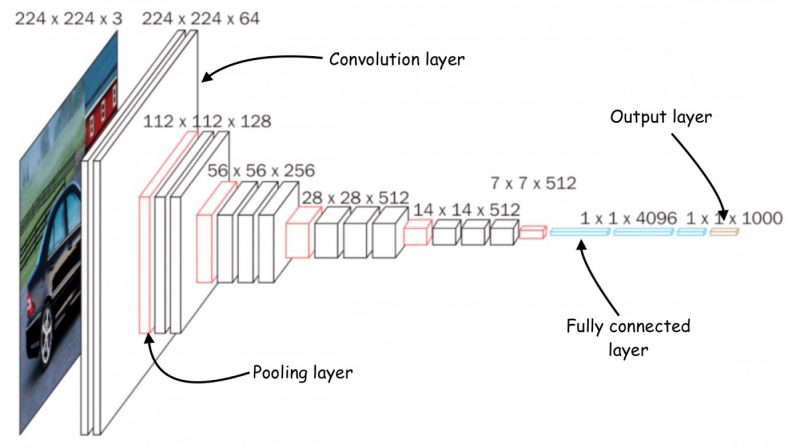
Deep learning models owe their initial success to large servers with large amounts of memory and clusters of GPUs. The promises of deep learning gave rise to an entire industry of cloud computing services for deep neural networks. Consequently, very large neural networks running on virtually unlimited cloud resources became very popular, especially among wealthy tech companies that can foot the bill. But at the same time, recent years have also seen a reverse trend, a concerted effort to create machine learning models for edge devices. Called tiny machine learning, or TinyML, these models are suited for devices that have limited memory and processing power, and in which internet connectivity is either non-present or limited. The latest in these efforts, a joint work by IBM and the Massachusetts Institute of Technology (MIT), addresses the peak-memory bottleneck of convolutional neural networks (CNN), a deep learning architecture that is especially critical for computer vision applications. Detailed in a paper presented at the NeurIPS 2021 conference, the model is called MCUNetV2 and can run CNNs on low-memory and low-power microcontrollers.
Why TinyML?
While deep learning in the cloud has been tremendously successful, it is not applicable in all situations. Many applications require on-device inference. For example, in some settings, such as drone rescue missions, internet connectivity is not guaranteed. In other domains, such as healthcare, privacy requirements and regulations make it very difficult to send data to the cloud for processing. And the delay caused by the roundtrip to the cloud is prohibitive for applications that require real-time ML inference. All these necessities have made on-device ML both scientifically and commercially attractive. Your iPhone now runs facial recognition and speech recognition on device. Your Android phone can run on-device translation. Your Apple Watch uses machine learning to detect movements and ECG patterns. These on-device ML models have partly been made possible by advances in techniques used to make neural networks compact and more compute- and memory-efficient. But they have also been made possible thanks to advances in hardware. Our smartphones and wearables now pack more computing power than a server did 30 years ago. Some even have specialized co-processors for ML inference. TinyML takes edge AI one step further, making it possible to run deep learning models on microcontrollers (MCU), which are much more resource-constrained than the small computers that we carry in our pockets and on our wrists. Microcontrollers are cheap, with average sales prices reaching under $0.50, and they’re everywhere, embedded in consumer and industrial devices. At the same time, they don’t have the resources found in generic computing devices. Most of them don’t have an operating system. They have a small CPU, are limited to a few hundred kilobytes of low-power memory (SRAM) and a few megabytes of storage, and don’t have any networking gear. They mostly don’t have a mains electricity source and must run on cell and coin batteries for years. Therefore, fitting deep learning models on MCUs can open the way for many applications.
Memory bottlenecks in convolutional neural networks
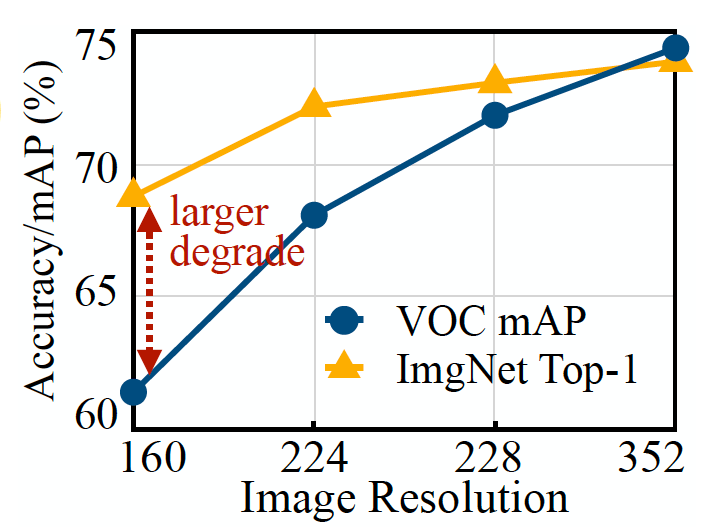
There have been multiple efforts to shrink deep neural networks to a size that fits on small-memory computing devices. However, most of these efforts are focused on reducing the number of parameters in the deep learning model. For example, “pruning,” a popular class of optimization algorithms, compress neural networks by removing the parameters that are not significant in the model’s output. The problem with pruning methods is that they don’t address the memory bottleneck of the neural networks. Standard implementations of deep learning libraries require an entire network layer and activation maps to be loaded into memory. Unfortunately, classic optimization methods don’t make any significant changes to the early layers of the network, especially in convolutional neural networks. This causes an imbalance in the size of different layers of the network and results in a “memory-peak” problem: Even though the network becomes lighter after pruning, the device running it must have as much memory as the largest layer. For example, in MobileNetV2, a popular TinyML model, the early layer blocks have a memory peak that reaches around 1.4 megabytes, while the later layers have a very small memory footprint. To run the model, a device will need as much memory as the model’s peak. With most MCUs having no more than a few hundred kilobytes of memory, they can’t run the off-the-shelf version of MobileNetV2. Another approach to optimizing neural networks is reducing the input size of the model. A smaller input image requires a smaller CNN to perform prediction tasks. However, reducing the input size presents its own challenges and is not efficient for all computer vision tasks. For example, object detection deep learning models are very sensitive to image size and their performance drops rapidly when the input resolution is reduced.
Patch-based inference with MCUNetV2
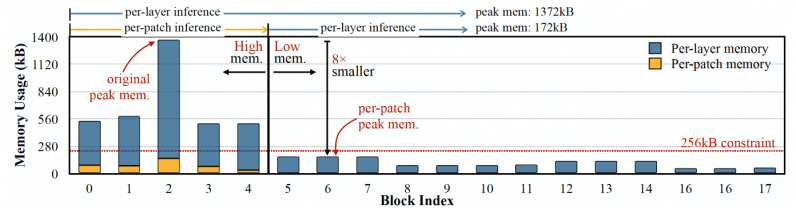
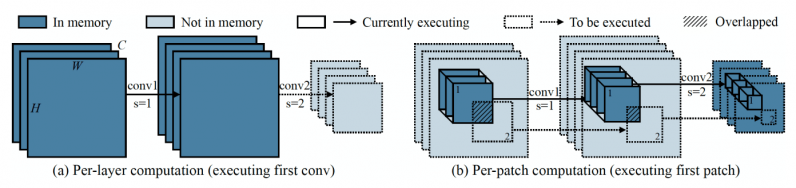
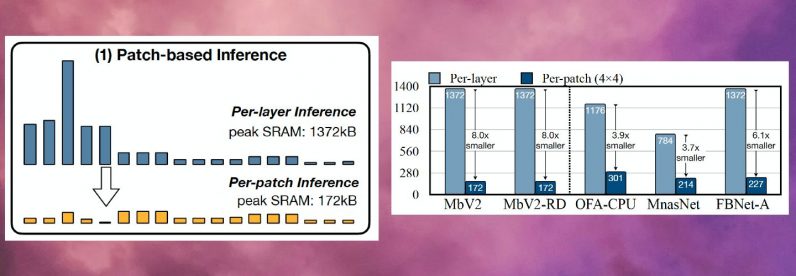
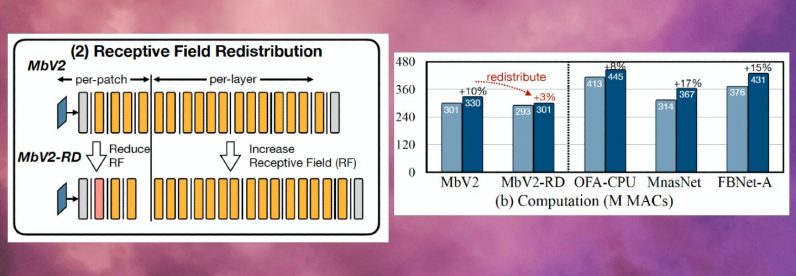
To address the memory bottleneck of convolutional neural networks, the researchers created called MCUNetV2, a deep learning architecture that can adjust its memory bandwidth to the limits of microcontrollers. MCUNetV2 builds on previous work by the same group, which was accepted and presented at the NeurIPS 2020 conference. The main idea behind MCUNetV2 is “patch-based inference,” a technique that reduces the memory footprint of CNNs without degrading their accuracy. Instead of loading an entire neural network layer into memory, MCUNetV2 loads and computes a smaller region—or a “patch”—of the layer at any given time. It then iterates across the entire layer patch by patch and combines the values until it computes activations for the entire layer. Since MCUNetV2 only needs to store one patch of neurons at a time, it cuts down the memory peak considerably without reducing the resolution or parameters of the model. The researchers’ experiments show that MCUNetV2 can reduce the memory peak by a factor of eight. The memory-saving benefits of patch-based inference come with a computation overhead tradeoff. The researchers from MIT and IBM found that the overall network computation could increase by 10-17 percent in different architectures, which is not suitable for low-powered microcontrollers. To overcome this limit, the researchers redistributed the “receptive field” of the different blocks of the network. In CNNs, the receptive field is the area of the image that is processed at any one moment. Larger receptive fields require larger patches and overlaps between patches, which creates a higher computation overhead. By shrinking the receptive fields of the initial blocks of the network and enlarging the receptive fields of the later stages, the researchers were able to reduce the computation overhead by more than two-thirds. Finally, the researchers observed that the adjustments of MCUNetV2 are largely dependent on the ML model architecture, the application, and the memory and storage capacity of the target device. To avoid manually tuning the deep learning model for every device and application, the researchers used “neural algorithmic search,” a process that uses machine learning to automatically optimize the architecture of the neural network and the inference scheduling. The researchers tested the deep learning architecture in different applications on several microcontroller models with small memory capacity. The results show that MCUNetV2 outperforms other TinyML techniques, reaching higher accuracy in image classification and object detection with smaller memory requirements and lower latencies. The researchers display MCUNetV2 in action using real-time person detection, visual wake words, and face/mask detection.
Applications of TinyML
In a 2018 essay titled “Why the Future of Machine Learning is Tiny,” software engineer Pete Warden argued that machine learning on MCUs is extremely important. “I’m convinced that machine learning can run on tiny, low-power chips, and that this combination will solve a massive number of problems we have no solutions for right now,” Warden wrote. Our ability to capture data from the world has increased immensely thanks to advances in sensors and CPUs. But our ability to process and use that data through machine learning models has been limited by network connectivity and access to cloud servers. As Warden argued, processors and sensors are much more energy-efficient than radio transmitters such as Bluetooth and wifi. “The physics of moving data around just seems to require a lot of energy. There seems to be a rule that the energy an operation takes is proportional to how far you have to send the bits. CPUs and sensors send bits a few millimeters, and is cheap, radio sends them meters or more and is expensive,” Warden wrote. “[It’s] obvious there’s a massive untapped market waiting to be unlocked with the right technology. We need something that works on cheap microcontrollers, that uses very little energy, that relies on compute not radio, and that can turn all our wasted sensor data into something useful. This is the gap that machine learning, and specifically deep learning, fills.” Thanks to MCUNetV2 and other advances in TinyML, Warden’s forecast is fast turning into a reality. In the coming years, we can expect TinyML to find its way into billions of microcontrollers in homes, offices, hospitals, factories, farms, roads, bridges, etc. to enable applications that were previously impossible.